Database normalization: how far to go (and when to stop)
Understand normal forms (1NF through 5NF), why to normalize, when to denormalize, and how to make practical decisions about database schema design.
Before normalization became standard practice, databases were messy. Data was duplicated everywhere, updates were nightmarish, and deletions could accidentally wipe out critical information. If you've ever worked with a legacy database where the same customer email appears in 47 different places—each spelled slightly differently—you know the pain.
This article takes you through database normalization from first principles to production patterns. You'll see how each normal form solves specific problems, understand when to denormalize strategically, and learn how normalization flows through your entire stack—from SQL tables to ORMs to frontend state management.
1. Fundamentals
What Is Normalization?
Normalization is the systematic process of organizing database tables to minimize redundancy and dependency issues. The goal is simple: store each piece of information exactly once and ensure that relationships between data are logically structured.
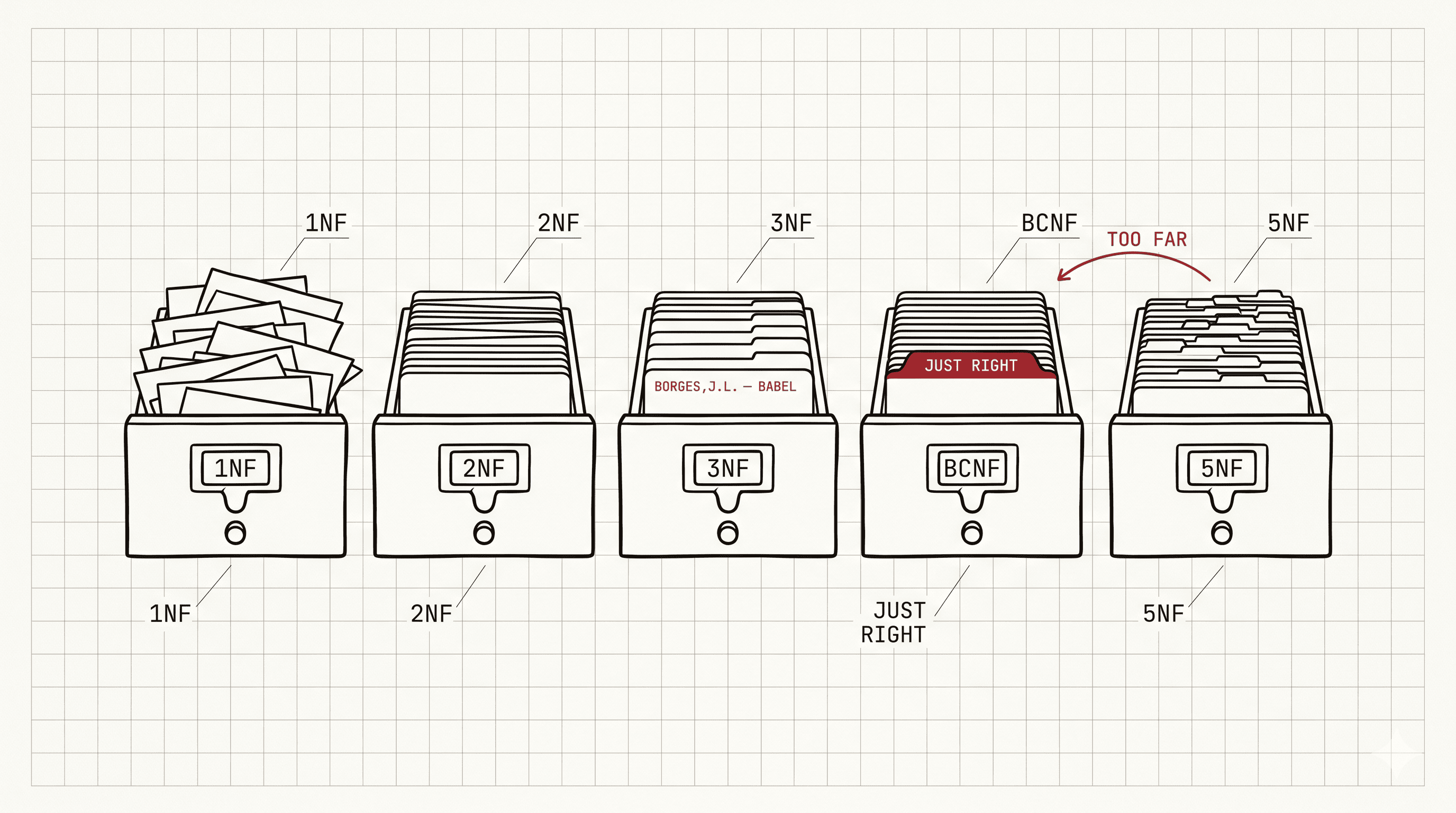
When you normalize a database, you're applying a series of rules (called "normal forms") that progressively eliminate data anomalies. Each normal form builds on the previous one, creating increasingly robust data structures.
Main Goal: Eliminate anomalies and ensure that each fact is stored in a single place.
Data Anomalies
Insertion Anomaly
You cannot insert data without having other unrelated data available.
Update Anomaly
Changing a piece of data requires multiple updates, risking inconsistency.
Deletion Anomaly
Deleting a record can cause unintentional loss of information.
Functional Dependencies
A functional dependency X → Y means "X determines Y" or "Y depends on X".
Types of Dependencies:
- Full Dependency: Attribute depends on the ENTIRE primary key
- Partial Dependency: Attribute depends on PART of the primary key (problem in 2NF)
- Transitive Dependency: A → B, B → C, therefore A → C (problem in 3NF)
2. Normal Forms
Comparison Table
| Normal Form | Key Requirement | What It Eliminates | Violation Example |
|---|---|---|---|
| 1NF | Atomic values, no repeating groups | Multiple values in a cell | phones: "555-1234, 555-5678" |
| 2NF | 1NF + no partial dependencies | Attributes depending on part of PK | (order_id, product_id) → product_name |
| 3NF | 2NF + no transitive dependencies | Attributes depending on non-key | order_id → customer_id → customer_name |
| BCNF | 3NF + every determinant is a candidate key | Dependencies with non-key determinant | professor → subject in (student, subject) |
| 4NF | BCNF + no multi-valued dependencies | Multiple independent N:M relationships | professor with multiple phones AND books |
| 5NF | 4NF + no join dependencies | Decompositions that lose information | Complex ternary relationships |
First Normal Form (1NF)
Rules:
- Each column contains atomic (indivisible) values
- No repeating groups
- Each record is unique (has a primary key)
Violation of 1NF
Correction to 1NF
Second Normal Form (2NF)
Rules:
- Must be in 1NF
- No partial dependencies (non-key attributes must depend on the ENTIRE composite primary key)
Violation of 2NF
Correction to 2NF
Third Normal Form (3NF)
Rules:
- Must be in 2NF
- No transitive dependencies (non-key attributes must not depend on other non-key attributes)
Violation of 3NF
Correction to 3NF
Boyce-Codd Normal Form (BCNF)
Rule: For every functional dependency X → Y, X must be a superkey (candidate key). Stricter than 3NF: In 3NF, if Y is part of the key, the dependency is allowed. BCNF does not allow this.
Violation of BCNF
Correction to BCNF
Fourth Normal Form (4NF)
Rule: Must not have non-trivial multi-valued dependencies. Multi-valued Dependency: A →→ B means that for each value of A, there is a set of values for B, independent of other attributes.
Violation of 4NF
Correction to 4NF
Fifth Normal Form (5NF)
5NF deals with join dependencies — situations where a table can only be decomposed without loss by breaking it into three or more smaller tables.
3. Complete E-commerce Example
Here's a fully normalized e-commerce schema demonstrating all principles in practice.
4. Denormalization Strategies
Materialized Views
Computed Columns with Triggers
5. ORM Integration
Prisma Schema
Solving N+1 with Prisma
Sequelize Associations
TypeORM Relations
6. Backend Layer (Node.js/Express)
Complex JOIN Queries
DataLoader for Batching (Solving N+1)
Data Serialization
7. Frontend Layer
How Normalized Data Arrives at the Frontend
Normalizr for State Management
Redux Toolkit with Normalized State
When the Frontend Needs to Understand the Structure
The frontend rarely needs to know about database normalization. BUT there are cases where it helps:
- Local cache: Avoid data duplication (Redux, Apollo Client)
- Optimistic updates: Knowing that updating user 500 affects all related orders
- Offline-first: Syncing normalized data locally (PouchDB, WatermelonDB)
8. NoSQL vs SQL
MongoDB: Embedding (Denormalized)
MongoDB: Referencing (Normalized)
When to Use Each Approach
| Scenario | Embedding (Denormalized) | Referencing (Normalized) |
|---|---|---|
| Data rarely changes | Ideal (e.g., order history) | Unnecessary overhead |
| Data changes frequently | Hard to keep in sync | Ideal (e.g., user profile) |
| 1:1 or 1:few relationship | Embed (e.g., address in order) | Unnecessary complexity |
| 1:many or N:M relationship | Document gets too large | References (e.g., order products) |
| Reads >> Writes | Embed for performance | Multiple queries needed |
| Writes >> Reads | Expensive updates | References for consistency |
DynamoDB Single-Table Design
In DynamoDB, you use a single table with composite keys (PK + SK) to store all entity types together. Data is modeled based on access patterns, not entities. For example, PK: "USER#500", SK: "ORDER#123" lets you query all orders for a user in one request. This is denormalized by nature — data is duplicated strategically because JOINs don't exist in DynamoDB.
9. Performance: Normalized vs Denormalized
| Operation | Normalized | Denormalized | Winner |
|---|---|---|---|
| Simple SELECT | SELECT * FROM orders WHERE id = 123 ~1ms | SELECT * FROM orders WHERE id = 123 ~1ms | Tie |
| SELECT with JOINs (3 tables) | JOIN users, addresses ~5-15ms | Data already embedded ~1-2ms | Denormalized |
| SELECT with JOINs (10+ tables) | ~50-200ms multiple heavy JOINs | ~2-5ms everything in 1 table | Denormalized |
| INSERT | 3 INSERTs (order, items, payment) ~3-5ms | 1 INSERT with JSON ~2ms | Denormalized |
| Simple UPDATE | 1 row update ~1ms | 100+ rows update ~50ms | Normalized |
| Cascade UPDATE | 1 UPDATE (FK cascade automatic) ~2ms | Multiple manual UPDATEs ~100ms+ | Normalized |
| DELETE | CASCADE deletes related rows ~10ms | Manually delete from multiple collections ~50ms+ | Normalized |
| Aggregations | GROUP BY on normalized data ~20ms | Same ~20ms | Tie |
| Consistency | ACID guaranteed, FK constraints | Possible inconsistencies, manual sync | Normalized |
| Disk Space | Minimal (no duplication) | Larger (duplicated data) | Normalized |
Index Strategies
EXPLAIN ANALYZE
Reading EXPLAIN ANALYZE:
- Seq Scan: Full table scan (slow). Create an index!
- Index Scan: Index lookup (fast)
- Index Only Scan: Everything from index, no table access (very fast)
- Nested Loop: Nested loop JOIN (good for few records)
- Hash Join: Hash table JOIN (good for many records)
- cost: Planner estimate (not real time)
- actual time: Real execution time (what matters!)
10. Decision Framework
When to NORMALIZE:
- Transactional system (OLTP) with many writes
- Data changes frequently
- Integrity and consistency are critical
- Complex relationships (N:M)
- Disk space is limited
- Compliance and auditing are necessary Examples: E-commerce, ERP, CRM, Banking
When to DENORMALIZE:
- Analytical system (OLAP) with many reads
- Data rarely changes (history, logs)
- Read performance is critical
- Complex queries with multiple JOINs
- Dashboards and reports
- Cached aggregated data Examples: Data Warehouse, Analytics, Dashboards, Logs
Decision Flowchart
+----------------------------------+
| Does your data change frequently?|
+----------+----------+------------+
| |
YES NO
| |
v v
+-----------+ +------------+
| NORMALIZE | | Reads > |
| | | Writes? |
+-----------+ +---+----+---+
| |
YES NO
| |
v v
+----------+ +----------+
|DENORMALIZE| |NORMALIZE |
|(cache, MV)| | |
+----------+ +----------+Hybrid Approach (Best of Both Worlds)
Final Checklist
| Question | If YES | If NO |
|---|---|---|
| Does data change frequently? | Normalize | Consider denormalizing |
| Is integrity critical? | Normalize (FK constraints) | Denormalization may work |
| Do queries have multiple JOINs? | Consider MV or cache | Normalization is fine |
| Is read performance critical? | Denormalize (MV, cache) | Normalization is fine |
| Is disk space limited? | Normalize | Denormalization is fine |
| Is it an OLTP (transactional) system? | Normalize | - |
| Is it an OLAP (analytical) system? | Denormalize | - |
| Do you need auditing/history? | Normalize (event sourcing) | - |
Conclusion
Normalization is not "all or nothing". In practice, the best systems use a hybrid approach:
- Normalize your WRITE MODEL (transactional tables) to guarantee integrity
- Denormalize strategically (Materialized Views, computed columns, cache) to optimize reads
- Document your decisions and monitor performance with EXPLAIN ANALYZE
- Iterate: Start normalized, denormalize where performance demands it
Don't optimize prematurely. Measure first, then optimize.